JavaScript 是单线程执行的,一次只能做一件事,未来也会继续是这样。
但是我们执行的代码通常看上去都是异步的,比如 ajax 的回调,setTimeout 等等。
代码看上去都不是同步执行的,JavaScript 是如何做到异步的呢?
答案就是事件循环。
JavaScript 内存图
(图片来自 MDN)
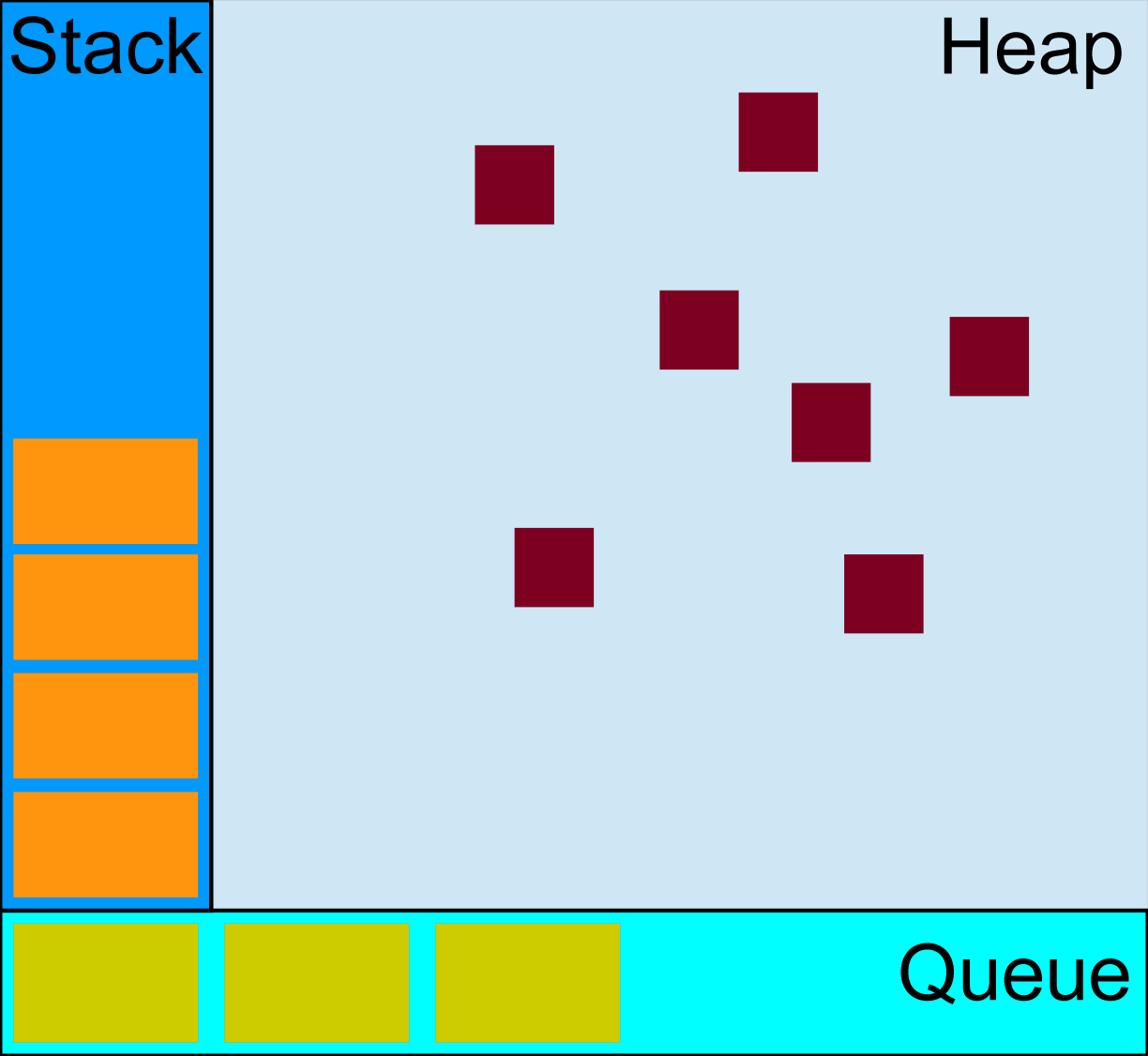
调用栈(Call Stack)
每个函数调用会产生一个栈帧。
当调用一个函数时,就会将这个函数帧压入调用栈的最上层中,帧中包含了局部变量,当函数执行完毕之后,最上层的帧就会被弹出栈,栈中的变量也会被清除,当所有函数执行完毕之后,栈就被清空了。
堆(Heap)
所有的对象都会被随机地分配在堆中。
队列(Queue)
队列中存放的就是待处理的事件回调函数。当调用栈中的所有帧都执行完了之后,就会执行事件循环。从先进入队列的回调函数开始,如果事件函数的条件符合,则会被移出队列,然后压入调用栈中执行,直到调用栈中的所有帧被清除,事件循环才会继续。
思考如下代码:
1 | function foo() { |
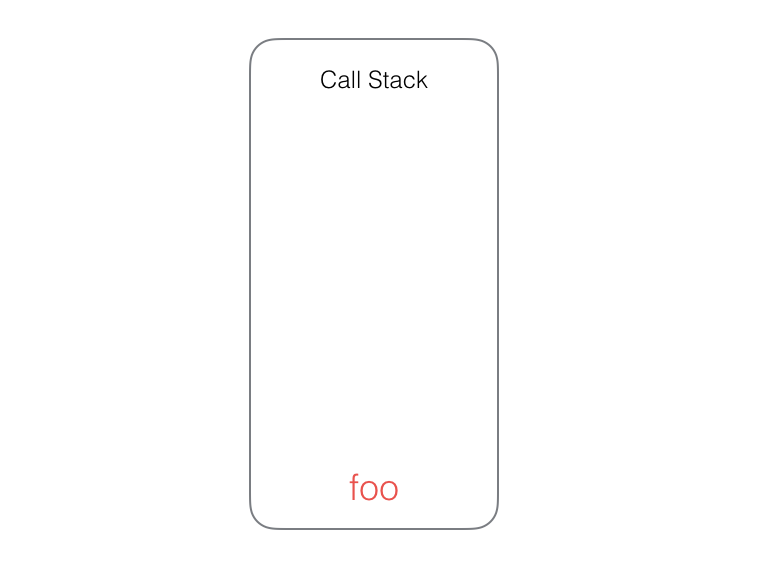
在这段代码中,先执行了 foo(),把 foo 函数压入调用栈中执行,此时调用栈中是这样的:
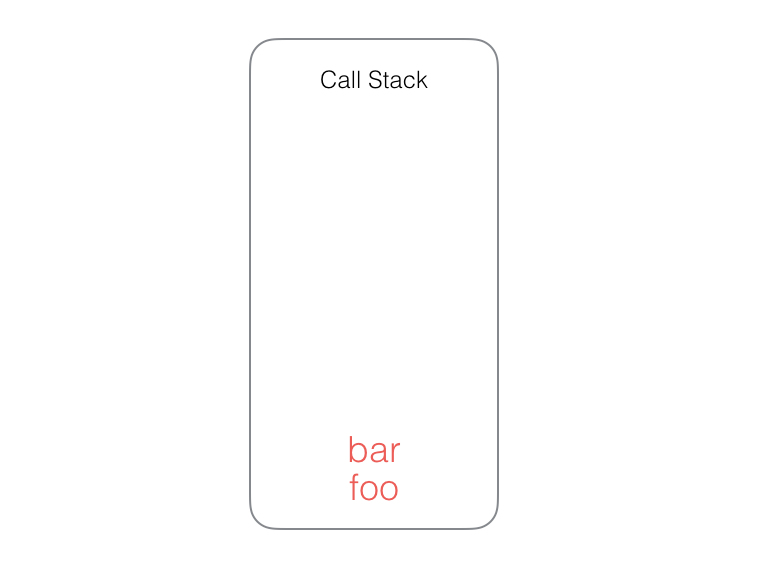
在 foo 函数中又执行了 bar 函数,把 bar 函数压入调用栈中执行,此时调用栈中是这样的:
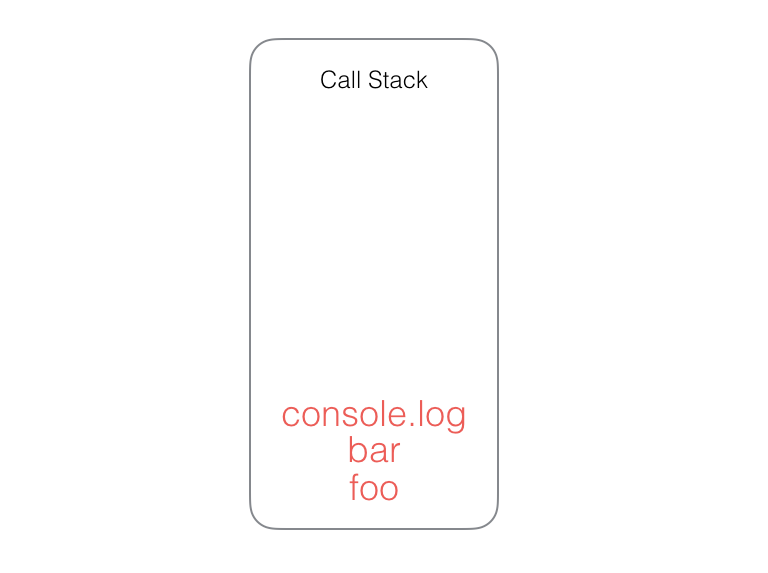
bar 函数中又调用了 console.log 函数,继续往栈中添加帧:
执行 console.log(1),在控制台打印 1,打印完毕之后,退出 console.log 函数,把执行环境交还给 bar 函数,此时栈中是这样的:
由于 bar 函数没有更多的代码需要执行,于是退出 bar 函数,把执行环境交还给 foo 函数:
foo 函数中也没有更多的代码,即退出 foo 函数,清空了调用栈。
把代码修改一下,方便看到栈信息:
1 | function foo() { |
在 chrome 中的 console 运行这段代码有以下的输出:

由于抛出错误时已经退出了 console.log 函数,所以在调用栈中看不到 console.log 函数。
最底下的 <anonymous> 函数就是全局执行环境(Global Execution Context)了。
以上的图示都只涉及到调用栈,再思考以下的代码:
1 | function foo() { |
这段代码首先通过 setTimeout 函数把 bar 函数和 baz 函数加入队列中,然后执行了 foo 函数,此时内存中应该是这样的:

当调用栈中的 foo 执行完毕,清空调用栈之后,就会开始事件循环,首先循环到 bar 函数,由于 bar 函数需要 1000 毫秒之后才执行,于是继续循环,到了 baz 函数,baz 函数是 0 毫秒执行的,于是把 baz 函数移出队列,加入到调用栈中执行,此时内存中应该是这样的:

baz 执行完之后,就清空了调用栈,就继续循环,等到 1000 毫秒后,并且循环到了 bar 函数时,则会把 bar 函数移出队列,压入调用栈执行:

bar 执行完毕之后,即清空了调用栈。
JavaScript 就是用事件循环的方式实现了异步和并发。
这样的方式与多线程并发对比的优点就在于不需要考虑资源竞争和锁,提高了编程的效率。
当然也有缺点,考虑以下代码:
1 | function foo() { |
bar 函数并不会像我们期待的那样在 1000 毫秒的时候执行,而是会在 1000 毫秒之后,或许甚至要 4000 毫秒之后执行,输出 2 到控制台。
首先执行了 setTimeout 把 bar 函数加入到队列中,再执行 foo 函数,foo 函数中含有一个非常耗时的同步操作,程序就会一直执行,直到 foo 函数执行完毕,把 foo 函数移出调用栈,事件循环才开始,当循环到 bar 函数时,由于此时已经距离 bar 被加入队列的时间超过了 1000 毫秒,所以 bar 函数会被立即移出队列,压入调用栈执行。
当然此处的 foo 函数的执行时间取决于具体运行的机器。
事实上,setTimeout 的第二个参数输入的 1000 毫秒的意思只是 至少要在 1000 毫秒 之后执行,而不是 刚好在 1000 毫秒的时候执行。
让调用栈“爆掉”
像我一样有恶趣味的人,可能就会开始想怎么样才能让调用栈“爆掉”。
一起思考如下代码:
1 | var count = 0; |
这段代码在我的 chrome 中运行输出了以下信息:
1 | RangeError: Maximum call stack size exceeded |
Maximum call stack size exceeded 表示超出了最大调用栈大小,frames count 后面的数字就表示调用栈可容纳的最大的函数帧数。
总结
- JavaScript 使用事件循环实现异步和并发;
- JavaScript 是单线程执行的,所以必须等到调用栈被清空之后才会开始事件循环;
- 事件循环时,只有队列中符合条件的函数才会被移出队列,并加入到栈中执行;
- 调用栈中容纳的函数帧数是有上限的;
参考
菲利普·罗伯茨:到底什么是 Event Loop 呢? | 欧洲 JSConf 2014